Enhance Existing Automatic Speech Recognition Model
Objective
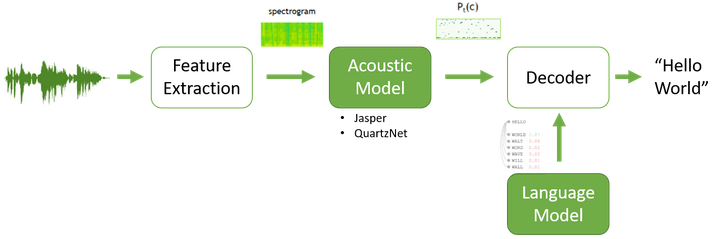
This is a well-established long-term project aimed at maintaining and enhancing the existing Automatic Speech Recognition (ASR) model or potentially developing a new one to yield superior results. My primary focus within this domain is on maintaining and advancing the traditional ASR model, which consists of two key components: an acoustic model (AM) and a language model (LM).
Over time, it became routine to collect new datasets from the client, acquire newly annotated (transcribed) speech audio datasets, prepare the data, and simultaneously train the LM and AM. Subsequently, these trained models were tested to assess their performance.