Design a noise robust VAD algorithm
Objective
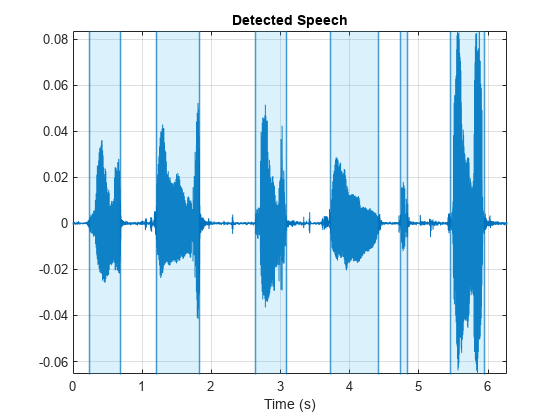
To enhance efficiency and accuracy, a novel approach to Voice Activity Detection (VAD) algorithm design was devised. VAD typically identifies silence segments within speech signal audio. By accurately detecting and localizing these segments, we can effectively segment the entire speech signal. This segmentation is crucial for reducing the computational cost of decoding in the Automatic Speech Recognition (ASR) model.
The entire VAD experiment process relies on digital signal processing algorithms. We deliberately avoided employing deep learning models to circumvent the feature extraction step within the VAD process. By directly applying DSP algorithms, we achieved a notable reduction in computational costs.